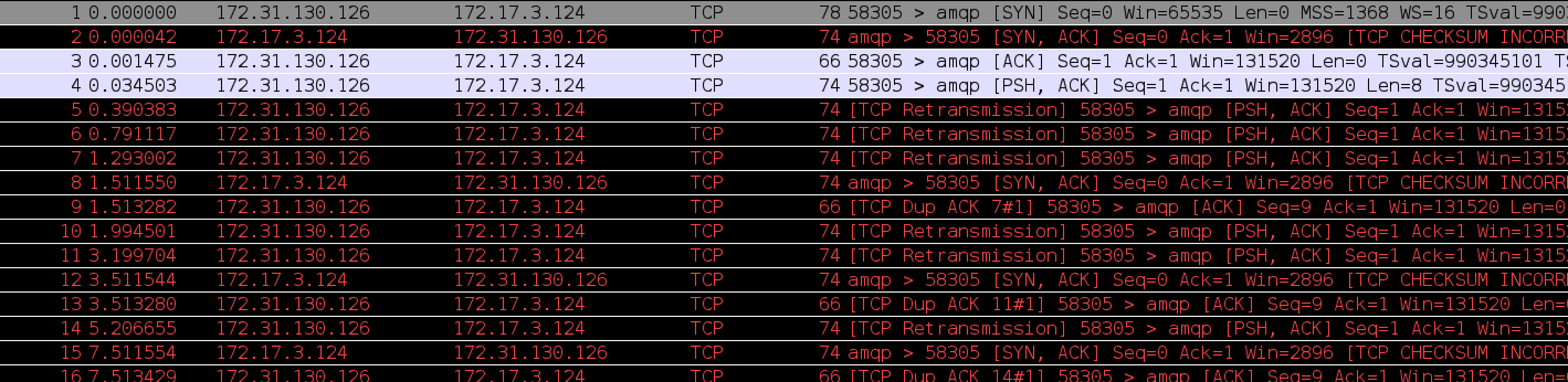
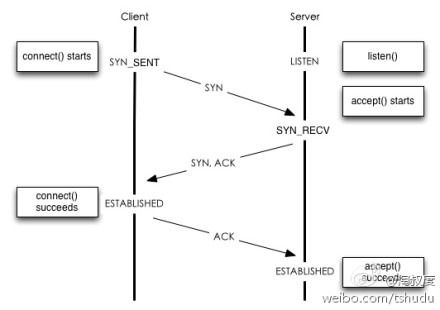
java.lang.Thread.State: BLOCKED (on object monitor) at com.netease.mq.client.AbstractSimpleClient.getChannel(AbstractSimpleClient.java:311) - waiting to lock <0x000000078b656bd8> (a com.netease.mq.client.producer.SimpleMessageProducer) at com.netease.mq.client.producer.SimpleMessageProducer.sendMessage(SimpleMessageProducer.java:78)
而持有锁的进程在等待Proxy的响应:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
java.lang.Thread.State: WAITING (on object monitor) at java.lang.Object.wait(Native Method) at java.lang.Object.wait(Object.java:485) at com.rabbitmq.utility.BlockingCell.get(BlockingCell.java:50) - locked <0x00000007866a31c8> (a com.rabbitmq.utility.BlockingValueOrException) at com.rabbitmq.utility.BlockingCell.uninterruptibleGet(BlockingCell.java:89) - locked <0x00000007866a31c8> (a com.rabbitmq.utility.BlockingValueOrException) at com.rabbitmq.utility.BlockingValueOrException.uninterruptibleGetValue(BlockingValueOrException.java:33) at com.rabbitmq.client.impl.AMQChannel$BlockingRpcContinuation.getReply(AMQChannel.java:343) at com.rabbitmq.client.impl.AMQChannel.privateRpc(AMQChannel.java:216) at com.rabbitmq.client.impl.AMQChannel.exnWrappingRpc(AMQChannel.java:118) at com.rabbitmq.client.impl.ChannelN.confirmSelect(ChannelN.java:1052) at com.rabbitmq.client.impl.ChannelN.confirmSelect(ChannelN.java:61) at com.netease.mq.client.AbstractSimpleClient.createChannel(AbstractSimpleClient.java:342) at com.netease.mq.client.AbstractSimpleClient.getChannel(AbstractSimpleClient.java:323) - locked <0x000000078b656bd8> (a com.netease.mq.client.producer.SimpleMessageProducer) at com.netease.mq.client.producer.SimpleMessageProducer.sendMessage(SimpleMessageProducer.java:78)
java.lang.Thread.State: WAITING (on object monitor) at java.lang.Object.wait(Native Method) at java.lang.Object.wait(Object.java:485) at com.rabbitmq.utility.BlockingCell.get(BlockingCell.java:50) - locked <0x000000078669fc98> (a com.rabbitmq.utility.BlockingValueOrException) at com.rabbitmq.utility.BlockingCell.get(BlockingCell.java:65) - locked <0x000000078669fc98> (a com.rabbitmq.utility.BlockingValueOrException) at com.rabbitmq.utility.BlockingCell.uninterruptibleGet(BlockingCell.java:111) - locked <0x000000078669fc98> (a com.rabbitmq.utility.BlockingValueOrException) at com.rabbitmq.utility.BlockingValueOrException.uninterruptibleGetValue(BlockingValueOrException.java:37) at com.rabbitmq.client.impl.AMQChannel$BlockingRpcContinuation.getReply(AMQChannel.java:349) at com.rabbitmq.client.impl.ChannelN.close(ChannelN.java:567) at com.rabbitmq.client.impl.ChannelN.close(ChannelN.java:499) at com.rabbitmq.client.impl.ChannelN.close(ChannelN.java:492) at com.netease.mq.client.AbstractSimpleClient$1.onRemoval(AbstractSimpleClient.java:255) at com.google.common.cache.LocalCache.processPendingNotifications(LocalCache.java:2016) at com.google.common.cache.LocalCache$Segment.runUnlockedCleanup(LocalCache.java:3521) at com.google.common.cache.LocalCache$Segment.postWriteCleanup(LocalCache.java:3497) at com.google.common.cache.LocalCache$Segment.remove(LocalCache.java:3168) at com.google.common.cache.LocalCache.remove(LocalCache.java:4236) at com.google.common.cache.LocalCache$LocalManualCache.invalidate(LocalCache.java:4815) at com.netease.mq.client.AbstractSimpleClient$2.shutdownCompleted(AbstractSimpleClient.java:352)