小模型(Small Language Model)信息汇总
随着人工智能领域的不断发展,语言模型也变得越来越重要。在这个领域中,小模型(Small Language Models)正逐渐崭露头角,与大模型(Large Language Models)相比,它们有着独特的特点和潜在的价值。这篇文章主要关注两点,模型的进展,推理的进展,特别是在消费级设备(PC,移动设备)相关的进展。
概念
小模型与大模型的区别
- 规模大小:最明显的差异是规模大小。大模型通常包括数百亿甚至上千亿个参数,而小模型则包含数十亿甚至更少的参数。
- 计算资源:大模型需要庞大的计算资源来进行训练和推理,这使得它们在运行时需要强大的硬件支持。相比之下,小模型可以在更加普通的硬件上运行,这使得它们更具可行性。
小模型的优势和价值
- 计算成本:小模型在计算成本上具有优势,因为它们不需要大规模的硬件支持。这使得它们成为中小企业、初创公司和研究团队的理想选择,因为它们可以更轻松地实现自然语言处理的功能。
- 更容易控制和定制:小模型更容易进行定制和控制,因为它们的规模较小,更容易理解和调整。这使得它们适用于需要特定定制解决方案的应用领域。
可能的问题
虽然小模型具有很多优势,但也存在一些潜在的问题:
- 性能限制:由于其较小的规模,小模型在某些任务上可能表现不如大模型。它们的语言理解和生成能力可能会受到限制,特别是在处理复杂或专业性的任务时。
- 知识覆盖范围:小模型的训练数据较小,因此它们的知识覆盖范围可能有限。对于某些领域的信息,它们可能无法提供足够的帮助。
模型进展
Phi-2
微软在 23.12 发布了 Phi-2:
Phi-2, a small language model (SLM) with 2.7 billion parameters.
Phi-2 is notable for its exceptional performance on various benchmarks, rivaling or surpassing models up to 25 times larger in size.
This achievement is attributed to innovative training approaches, including the use of high-quality “textbook-quality” data and techniques for scaling knowledge transfer.
Despite its smaller size, Phi-2 demonstrates advanced reasoning and language understanding capabilities.
一个只有 2.7B 参数的模型,但效果与 llama 2 70B 及 Mistral 7B 差不多: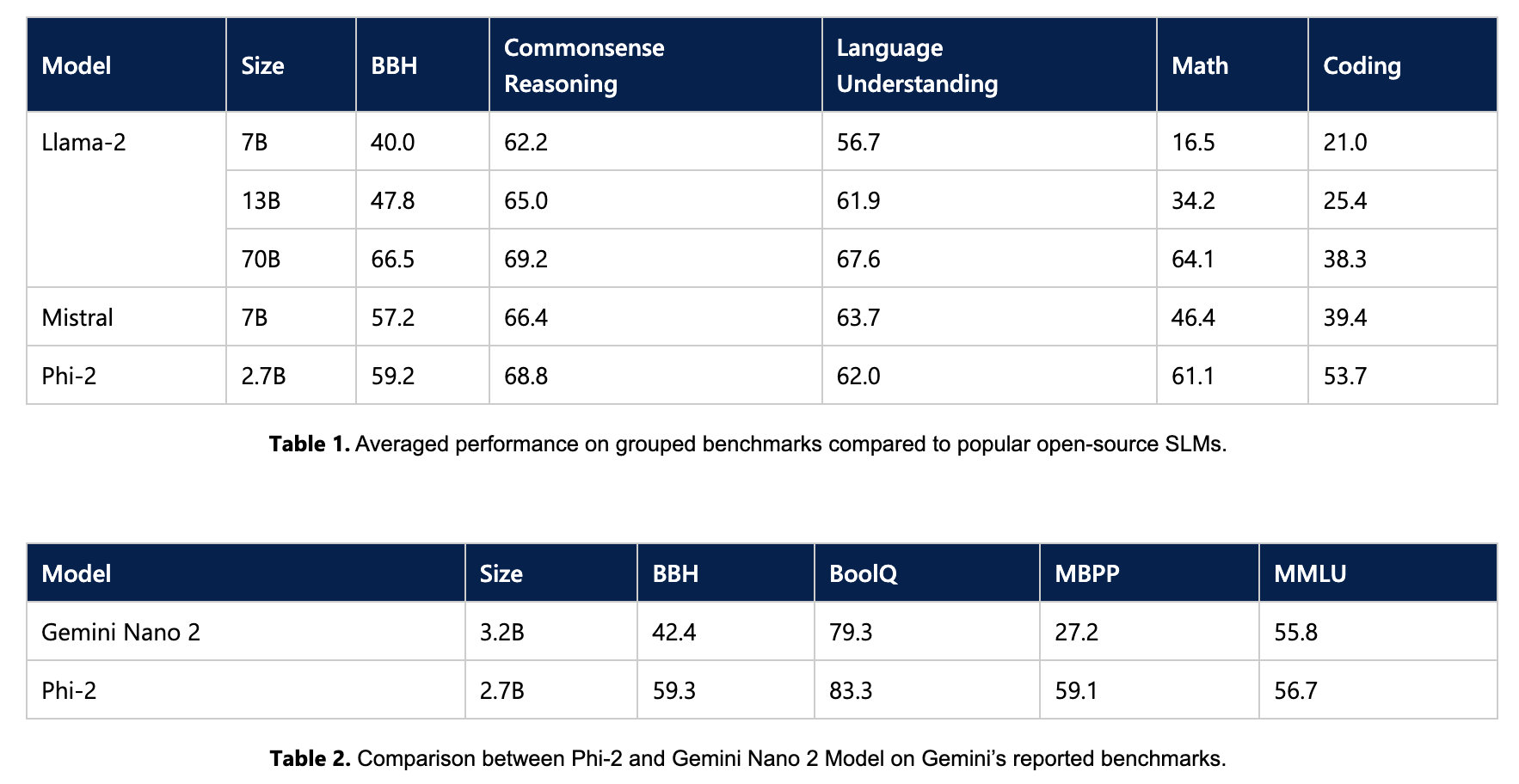
训练数据规模
Phi-2 is a Transformer-based model with a next-word prediction objective, trained on 1.4T tokens from multiple passes on a mixture of Synthetic and Web datasets for NLP and coding.
The training for Phi-2 took 14 days on 96 A100 GPUs.
做个对比:
GPT-3: 174B parameters. Phi-2: 2.7B parameters.
GPT-3: trained with 300B tokens. Phi-2: trained with 1400B tokens.
Key Insights Behind Phi-2
Firstly, training data quality plays a critical role in model performance. This has been known for decades, but we take this insight to its extreme by focusing on “textbook-quality” data, following upon our prior work “Textbooks Are All You Need.”
Secondly, we use innovative techniques to scale up, starting from our 1.3 billion parameter model, Phi-1.5, and embedding its knowledge within the 2.7 billion parameter Phi-2.
看起来除了技术上的革新外,最重要的就是用高质量的数据训练模型。
Phi-2 一开始出来时候,licensed 只能用于研究,但是在前几天改成了 MIT,就是说随便用。国内已经有学校基于 Phi-2 搞多模态模型了。
Mistral 7B
Mistral 7B 现在在开源社区用的比较多,很多人基于 Mistral 7B 做一些小的应用,比如 private local 的个人助理之类的。
Mistral 7B 是迄今为止同等规模中最强大的语言模型。作为一个拥有7.3亿参数的模型,Mistral 7B在所有基准测试中均优于13亿参数的Llama 2,并在许多基准测试中超越了34亿参数的Llama 1。更令人瞩目的是,Mistral 7B在代码领域的表现接近7B的CodeLlama,同时在英语任务上依然表现出色。
Mistral 7B采用了两项创新技术:分组查询注意力(Grouped-query Attention, GQA)和滑动窗口注意力(Sliding Window Attention, SWA),使得其在处理更长序列时成本更低,推理速度更快。此外,它还在Apache 2.0许可下发布,无限制地供用户使用。
这款模型不仅易于在任何任务上进行微调,而且在聊天方面的微调模型甚至超越了Llama 2的13亿参数聊天模型。Mistral 7B的表现在多个领域均十分出色,尤其在常识推理、世界知识、阅读理解、数学和编码等多个基准测试中显示了显著的优势。特别值得一提的是,在推理、理解和STEM(科学、技术、工程和数学)推理(MMLU)方面,Mistral 7B的表现相当于其三倍大小的Llama 2模型,这意味着在内存和吞吐量方面的显著节省。
Mistral 7B的滑动窗口注意力(SWA)机制是其主要的创新点,每层关注前4,096个隐藏状态,实现了线性计算成本。该模型在序列长度为16k和窗口大小为4k的情况下,实现了2倍的速度提升。此外,固定的注意力范围意味着可以将缓存限制在sliding_window大小的标记中,这在不影响模型质量的情况下,节省了一半的缓存内存。
Mistral 还有个 8*7B 的 MoE(Mixtral of Experts)模型,效果也是很不错,号称现在最强开源模型。
什么是 MoE?
Sparse MoE layers are used instead of dense feed-forward network (FFN) layers. MoE layers have a certain number of “experts” (e.g. 8), where each expert is a neural network. In practice, the experts are FFNs, but they can also be more complex networks or even a MoE itself, leading to hierarchical MoEs!
A gate network or router, that determines which tokens are sent to which expert.
简单讲就是一个门控网络+多个“专家“网络,门控网络负责将 token 路由到一个或者多个”专家“网络。
推理进展
有了小的合适的模型,那怎么在消费级设备上运行大模型?
Machine Learning Compilation for LLM
MLC 是 陈天奇 出的一个针对 LLM 做的一个推理部署解决方案,大致的逻辑如下图,包含三个部分: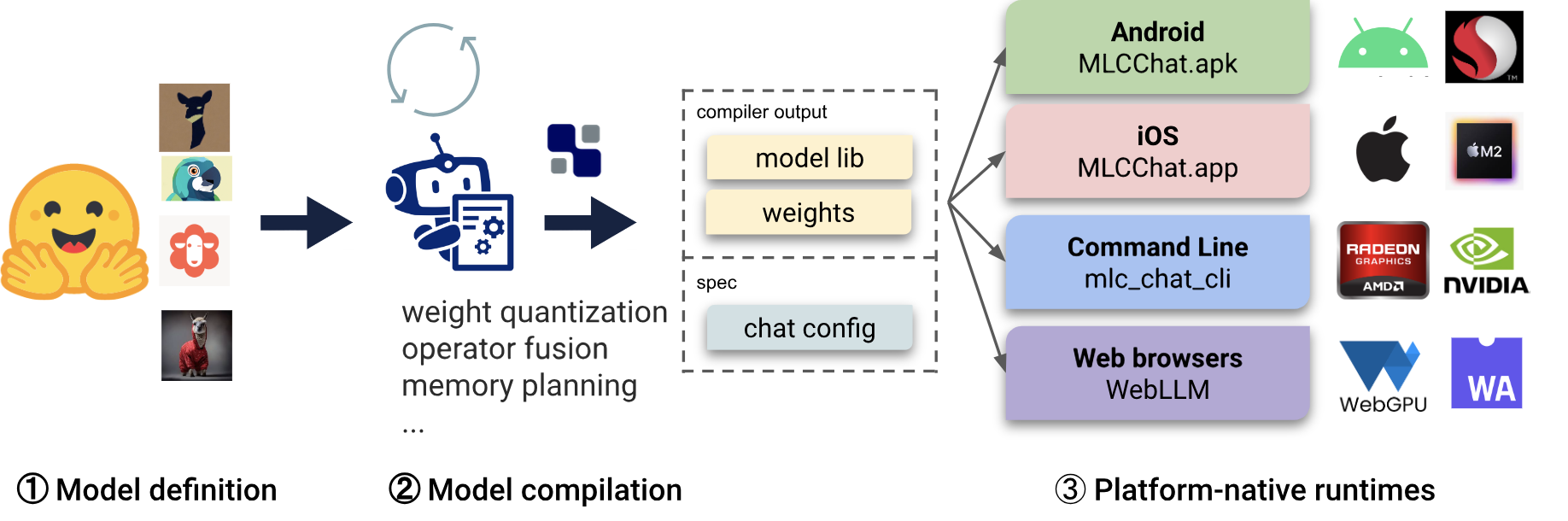
- Model definition in Python. MLC offers a variety of pre-defined architectures, such as Llama (e.g., Llama2, Vicuna, OpenLlama, Wizard), GPT-NeoX (e.g., RedPajama, Dolly), RNNs (e.g., RWKV), and GPT-J (e.g., MOSS). Model developers could solely define the model in pure Python, without having to touch code generation and runtime.
- Model compilation in Python. Models are compiled by TVM Unity compiler, where the compilation is configured in pure Python. MLC LLM quantizes and exports the Python-based model to a model library and quantized model weights. Quantization and optimization algorithms can be developed in pure Python to compress and accelerate LLMs for specific usecases.
- Platform-native runtimes. Variants of MLCChat are provided on each platform: C++ for command line, Javascript for web, Swift for iOS, and Java for Android, configurable with a JSON chat config. App developers only need to familiarize with the platform-naive runtimes to integrate MLC-compiled LLMs into their projects.
关键的三个部分:1)标准化的模型定义;2)模型编译及优化;3)平台相关的运行时(比如针对 iOS,Android等的运行时)。看起来像不像 Java 的逻辑:字节码,编译器,平台相关的运行时。所以可以叫跨平台大模型推理?
llama.cpp
Why llama.cpp?
However, practical applications of LLMs can be limited by the need for high-powered computing or the necessity for quick response times. These models typically require sophisticated hardware and extensive dependencies, which can make difficult their adoption in more constrained environments.
This is where LLaMa.cpp (or LLaMa C++) comes to the rescue, providing a lighter, more portable alternative to the heavyweight frameworks.
虽然 llama.cpp 一开始的目标是在 MacBook 上运行开源模型 LLaMA,但实际上发展到现在不仅限于此,也支持 Windows,Linux 等 PC 平台,以及 iOS,Android 等移动平台,支持的模型也越来越多。
Apple
CoreML
Apple CoreML是苹果公司专为iOS和macOS设备开发的一款强大的机器学习框架。这个框架的核心目标是使开发者能够轻松地在苹果设备上集成和运行各种机器学习模型,从而提供丰富和智能的用户体验。
CoreML的设计注重高效性和易用性。它支持多种流行的机器学习模型,如神经网络、决策树、支持向量机等,同时还提供了一系列的工具和接口,方便开发者将训练好的模型转换为CoreML格式并集成到应用中。这意味着开发者可以在其他平台(例如TensorFlow或PyTorch)上训练模型,然后轻松地迁移到iOS设备上。
CoreML的另一个亮点是其对硬件的优化。它能够充分利用苹果设备上的CPU、GPU以及专门的神经网络硬件加速器(如Apple Neural Engine),从而实现高效的模型运行。这种优化确保了应用在执行机器学习任务时的响应速度和能效。
除了性能优化,CoreML还特别重视隐私保护。所有的模型推理操作都在设备本地完成,不需要将用户数据发送到云端。这不仅加快了处理速度,也为用户数据的安全和隐私提供了额外的保障。
LLM in a Flash
Apple 曾在 23.12 月份发表了一篇论文:LLM in a Flash,尝试用更小的内存运行尽可能大的模型。
The paper “LLM in a Flash: Efficient Large Language Model Inference with Limited Memory” explores methods to efficiently run large language models (LLMs) on devices with limited memory.
The key focus is on using flash memory for storing model parameters, with selective loading into DRAM based on demand.
Two main techniques are introduced: “windowing,” which reduces data transfer by reusing previously activated neurons, and “row-column bundling,” which optimizes data chunk sizes for flash memory reading.
These methods enable running models up to twice the size of available DRAM with significantly increased inference speed.
This approach paves the way for effective LLM inference on devices with limited memory, enhancing model accessibility and application potential in resource-constrained environments.
Stable Diffusion on Apple Silicon
早在 22.12 月 Apple 就发表了一篇文章关于如何在 macOS 或者 iOS 上运行 Stable Diffusion:Stable Diffusion with Core ML on Apple Silicon
There are a number of reasons why on-device deployment of Stable Diffusion in an app is preferable to a server-based approach.
First, the privacy of the end user is protected because any data the user provided as input to the model stays on the user’s device.
Second, after initial download, users don’t require an internet connection to use the model.
Finally, locally deploying this model enables developers to reduce or eliminate their server-related costs.
为啥要在个人设备上运行 SD:1)隐私;2)不需要网络;3)成本。苹果提供了一个 Python 包可以帮你把 PyTorch 模型转换成 CoreML 模型,以及一个可以用于部署模型的 Swift 包。
个人想法
- 苹果在大模型上没啥声音,是不是在憋大招?现在的大模型准入门槛太高,大部分的团队及个人都玩不起,但如果苹果的设备上带了一个性能不错的小模型,会带来啥变化?如果小模型被手机或者设备厂商以标准化的服务或者接口提供出来,应该会催生很多 AI Native 的应用;
- 小模型在隐私及成本上有先天的优势,模型所需要的计算资源由用户提供。现在各个大厂出的应用(通义千问,文心一言,ChatGPT等)现在都是免费随便用,但这背后都需要大量资源或者钱来支撑,如果以后需要收钱来覆盖成本,用户有多大的意愿持续付钱?AI 时代的工具类应用未必会基于大模型,而有可能基于小模型,大模型所需要的算力成本在目前这个经济下行的趋势下,可能无法支撑工具类应用大规模传播。另一方面,类似个人助理这样的应用,有一些场景有很强的隐私性,小模型不需要网络的特性很可能更合适;
- 小模型的知识覆盖问题能不能用RAG解决?或者有更好更强的解决方案?
- 以后也许会出现两条战线:一条向上卷越来越多的参数,更广的知识覆盖,更高的精度,更好的效果,可能适合 2B 及一些对效果有强要求的场景;另一条卷更高质量的训练数据及更强的推理能力,用更小的模型结合RAG之类的技术提供不错的效果,可能适合2C;
- 很有可能以后占据手机的不是大模型,而是小模型,手机厂商可能会成为赢家(华为真是赢麻了。。。)。