消息队列系统存储架构演进
消息队列(Message Queue)是一种在消息的传递过程中存储消息的机制,广泛应用于系统解耦、流量削峰、数据同步等场景。本文将重点讨论三种流行的消息队列技术的存储架构(RocketMQ、Kafka和Pulsar)以及当前的演变趋势。
RocketMQ 存储
RocketMQ是阿里巴巴开源的消息中间件,基于高性能、高吞吐量设计。它采用了分布式、队列模型,能够保证消息的可靠传输。
存储架构
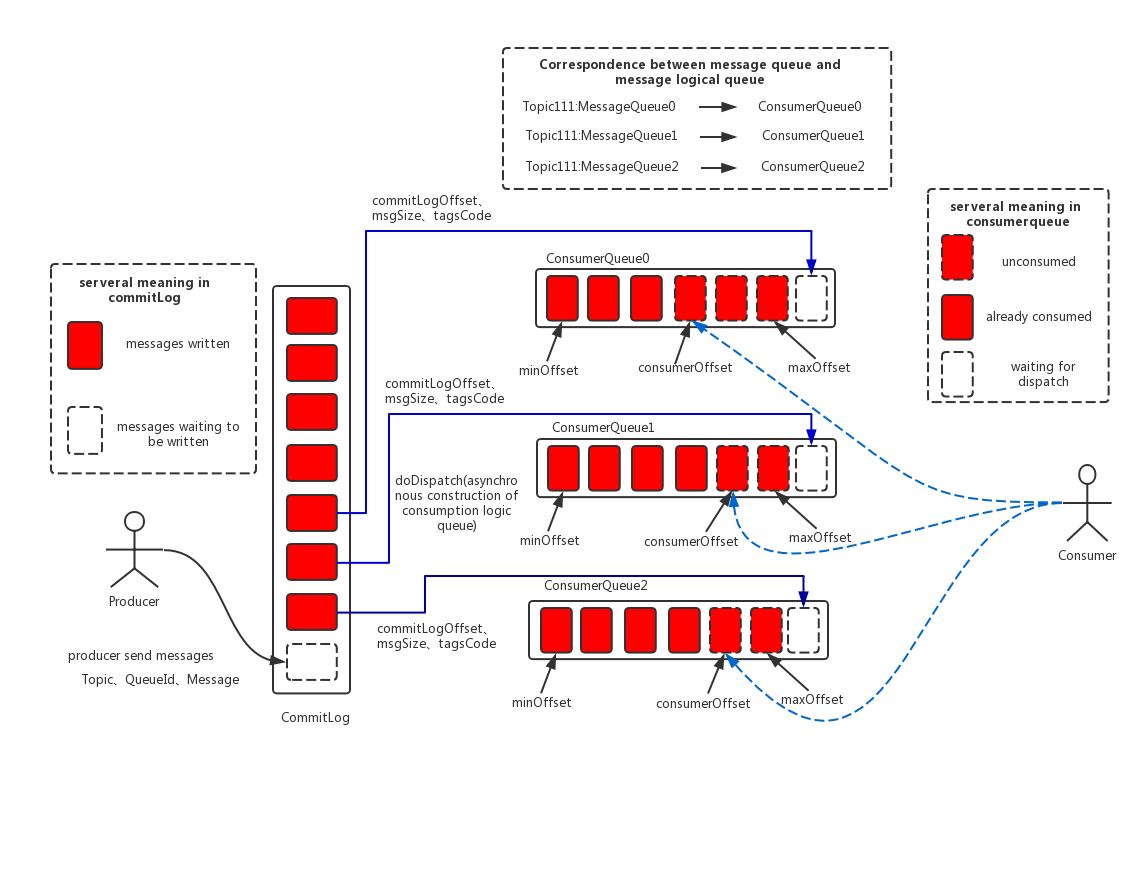
消息存储架构图中主要有下面三个跟消息存储相关的文件构成。
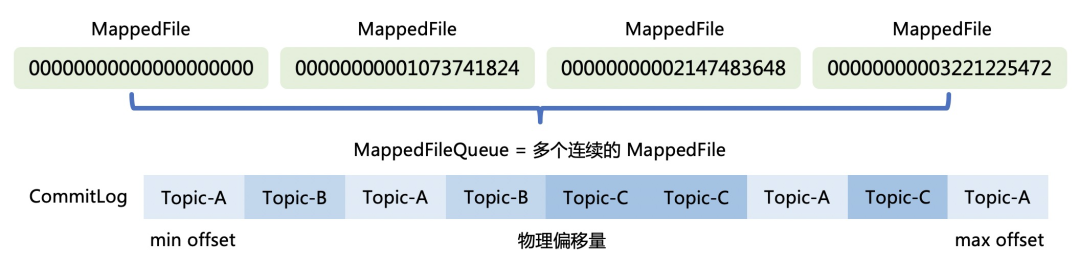
CommitLog:所有topic共享一个文件(逻辑上一个文件,物理上按固定大小分割成多个文件),是消息主体以及元数据的存储主体,存储Producer端写入的消息主体内容,消息内容不是定长的。单个文件大小默认1G, 文件名长度为20位,左边补零,剩余为起始偏移量,比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当第一个文件写满了,第二个文件为00000000001073741824,起始偏移量为1073741824,以此类推。消息主要是顺序写入日志文件,当文件满了,写入下一个文件;
ConsumeQueue:消息消费索引,引入的目的主要是提高消息消费的性能。由于RocketMQ是基于主题topic的订阅模式,消息消费是针对主题进行的,如果要遍历commitlog文件,根据topic检索消息是非常低效的。Consumer可根据ConsumeQueue来查找待消费的消息。其中,ConsumeQueue作为消费消息的索引,保存了指定Topic下的队列消息在CommitLog中的起始物理偏移量offset,消息大小size和消息Tag的HashCode值。
IndexFile:IndexFile(索引文件)提供了一种可以通过key或时间区间来查询消息的方法。Index文件的存储位置是:$HOME/store/index/{fileName},文件名fileName是以创建时的时间戳命名的,固定的单个IndexFile文件大小约为400M,一个IndexFile可以保存 2000W个索引,IndexFile的底层存储设计为在文件系统中实现HashMap结构,故RocketMQ的索引文件其底层实现为hash索引。
高可用机制(Master/Slave)
- Slave通过HAClient向Master上报同步到的最新commitOffset,HAConnection.ReadSocketService(Master)记录各个slave的同步位置;
- HAConnection.WriteSocketService(Master)不断检测slaveRequestOffset是否落后于Master最新offset,如果落后,则向Slave传输最新的commit log;
- 写入消息到本地commitLog后,如果Master是Master_SYNC,则会触发一次Master到Slave的数据传输,Slave收到最新commitLog后,立即向Master汇报最新的offset,Master收到匹配的最新offset后,向客户端返回Master/Slave写入成功。
Kafka 存储
Kafka由LinkedIn开发,后成为Apache项目。它是一个分布式流处理平台。
存储架构
与RocketMQ最大的不同是,Kafka每一个topic的partition都有一个独立的类似commitlog的文件,而RocketMQ是所有topic共享一个,这与RocketMQ及Kafka在设计时的初衷有关:Kafka定位于大规模数据或者说日志处理系统,topic不会很多,而RocketMQ定位于服务于业务的消息系统,天然的需要不同的topic来隔离不同的业务,而对Kafka来讲,更多的topic带来更多的文件句柄消耗,以及从单一的文件顺利读写变成随机读写,对性能影响很大。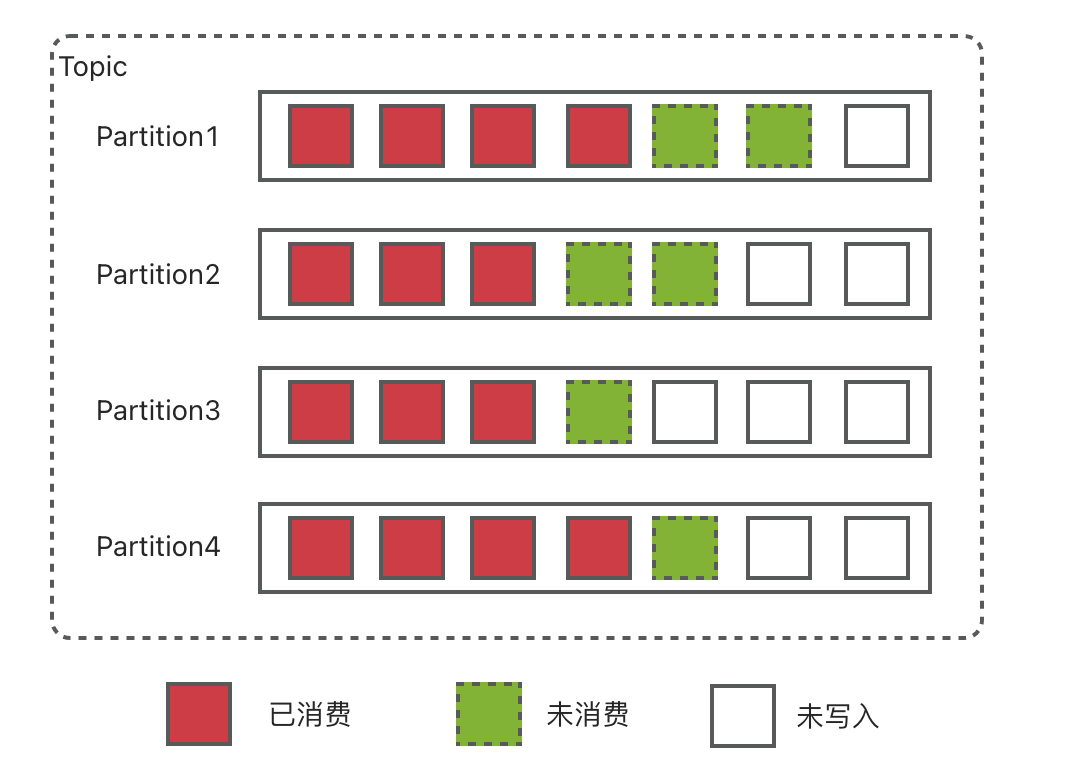
每个 partition 存储有三个文件:
- 日志文件(xx.log):作用与 RocketMQ 的 commitlog 文件类似,保存原始消息数据
- 索引文件(xx.index):作用与 RocketMQ 的 consumerqueue 文件类似,保存消息 offset 以及消息物理存储信息(在xx.log文件中的位置);
- TimeIndex 文件(xx.timeindex):作用与 RocketMQ 的 indexfile 文件类似,保存消息创建时间以及消息物理存储信息(在xx.log文件中的位置),为了支持类似按创建时间搜索或者过滤消息的功能;
Partition
Partition提供并行处理的能力,Partition是最小并发粒度。但更多的partition也会带来问题:
- More Partitions Lead to Higher Throughput;
- More Partitions Requires More Open File Handles:two files,one for the index and another for the actual data per log segment;
- More Partitions May Increase Unavailability:when a broker is shut down uncleanly (e.g., kill -9), the observed unavailability could be proportional to the number of partitions(每个partition都需要切主,更多的partition需要更多的时间完成切主,对于排在最后的partition,不可用的时间变长);
- More Partitions May Increase End-to-end Latency:By default, a Kafka broker only uses a single thread to replicate data from another broker, for all partitions that share replicas between the two brokers.(相同的broker之间,默认只有一个同步线程,更多的partition需要更多的时间同步)
- More Partitions May Require More Memory In the Client:客户端缓存;
高可用机制:ISR
Kafka的数据复制是以Partition为单位的。而多个备份间的数据复制,通过Follower向Leader拉取数据完成。从一这点来讲,Kafka的数据复制方案接近于Master-Slave方案。不同的是,Kafka既不是完全的同步复制,也不是完全的异步复制,而是基于ISR的动态复制方案。
ISR,也即In-sync Replica。每个Partition的Leader都会维护这样一个列表,该列表中,包含了所有与之同步的Replica(包含Leader自己)。每次数据写入时,只有ISR中的所有Replica都复制完,Leader才会将其置为Commit,它才能被Consumer所消费。
如何选主?
ISR中的broker先到先得,谁先在ZK上注册信息,谁就是leader。
如何判断某个Follower是否“跟上”Leader?
- 0.8.x版本,如果Follower在replica.lag.time.max.ms时间内未向Leader发送Fetch请求(也即数据复制请求),则Leader会将其从ISR中移除。如果某Follower持续向Leader发送Fetch请求,但是它与Leader的数据差距在replica.lag.max.messages以上,也会被Leader从ISR中移除。
- 0.9.0.0版本及以上,replica.lag.max.messages被移除;
为什么使用ISR?跟Raft,Paxos之类的Majority Quorum相比有什么区别?
- 由于Leader可移除不能及时与之同步的Follower,故与同步复制相比可避免最慢的Follower拖慢整体速度,也即ISR提高了系统可用性;
- ISR中的所有Follower都包含了所有Commit过的消息,而只有Commit过的消息才会被Consumer消费,故从Consumer的角度而言,ISR中的所有Replica都始终处于同步状态,从而与异步复制方案相比提高了数据一致性。
- ISR可动态调整,极限情况下,可以只包含Leader,极大提高了可容忍的宕机的Follower的数量。与Majority Quorum方案相比,容忍相同个数的节点失败,所要求的总节点数少了近一半。
Pulsar 存储
Pulsar是由Yahoo开发的一个分布式发布订阅消息系统。
整体架构
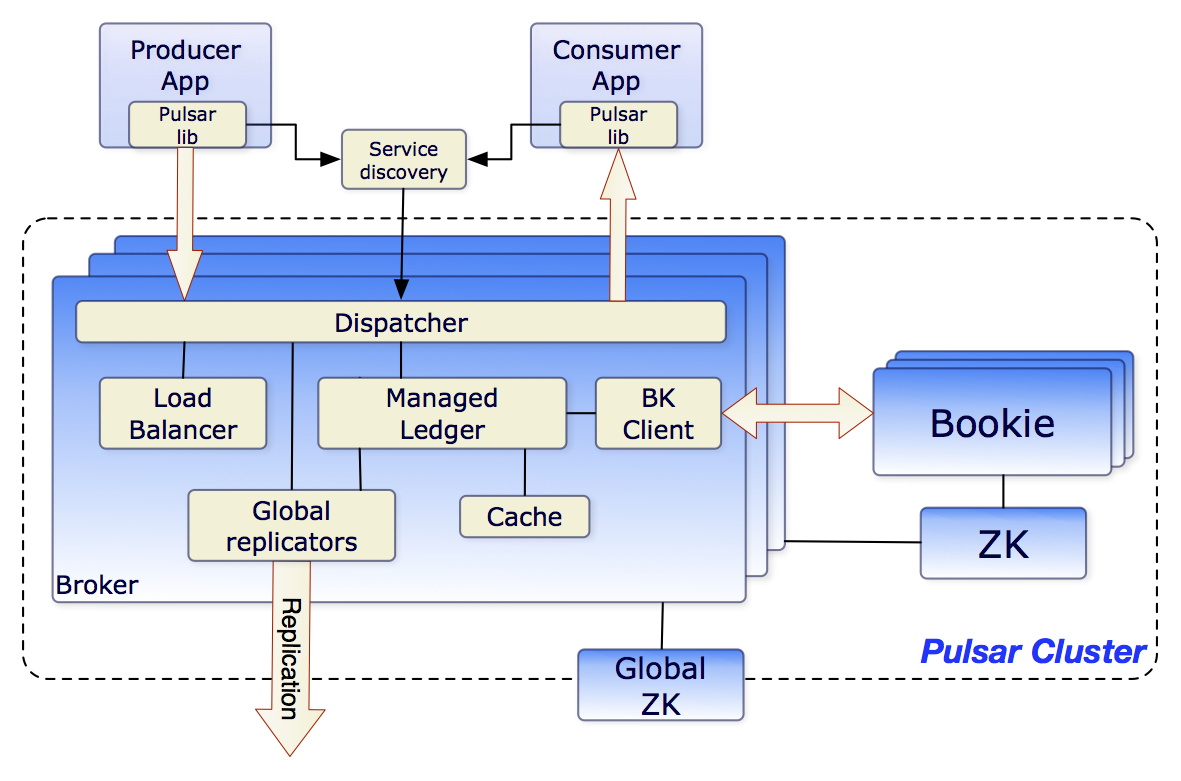 相比 RocketMQ 以及 Kafka,Pulsar 最大的不同是,从一开始就是计算存储分离的架构,broker 不再负责存储,存储完全由 bookkeeper 来负责,消息的高可用保证也完全由 bookkeeper 来提供。BookKeeper是一个高可靠性和高性能的分布式日志存储系统。
相比 RocketMQ 以及 Kafka,Pulsar 最大的不同是,从一开始就是计算存储分离的架构,broker 不再负责存储,存储完全由 bookkeeper 来负责,消息的高可用保证也完全由 bookkeeper 来提供。BookKeeper是一个高可靠性和高性能的分布式日志存储系统。
存储架构
基本概念:
ledger: streams of log entries are called ledgers
bookie: individual servers storing ledgers of entries are called bookies
在Pulsar中,每个Topic的消息存储在一个或多个Ledger中。当一个Ledger达到一定的大小或时间阈值,Pulsar会关闭当前Ledger并创建一个新的Ledger。Ledger 可以被拆分成多个 Segment,为了保障存储的高可用,每个 Segment 一般都会被分布到多台机器上。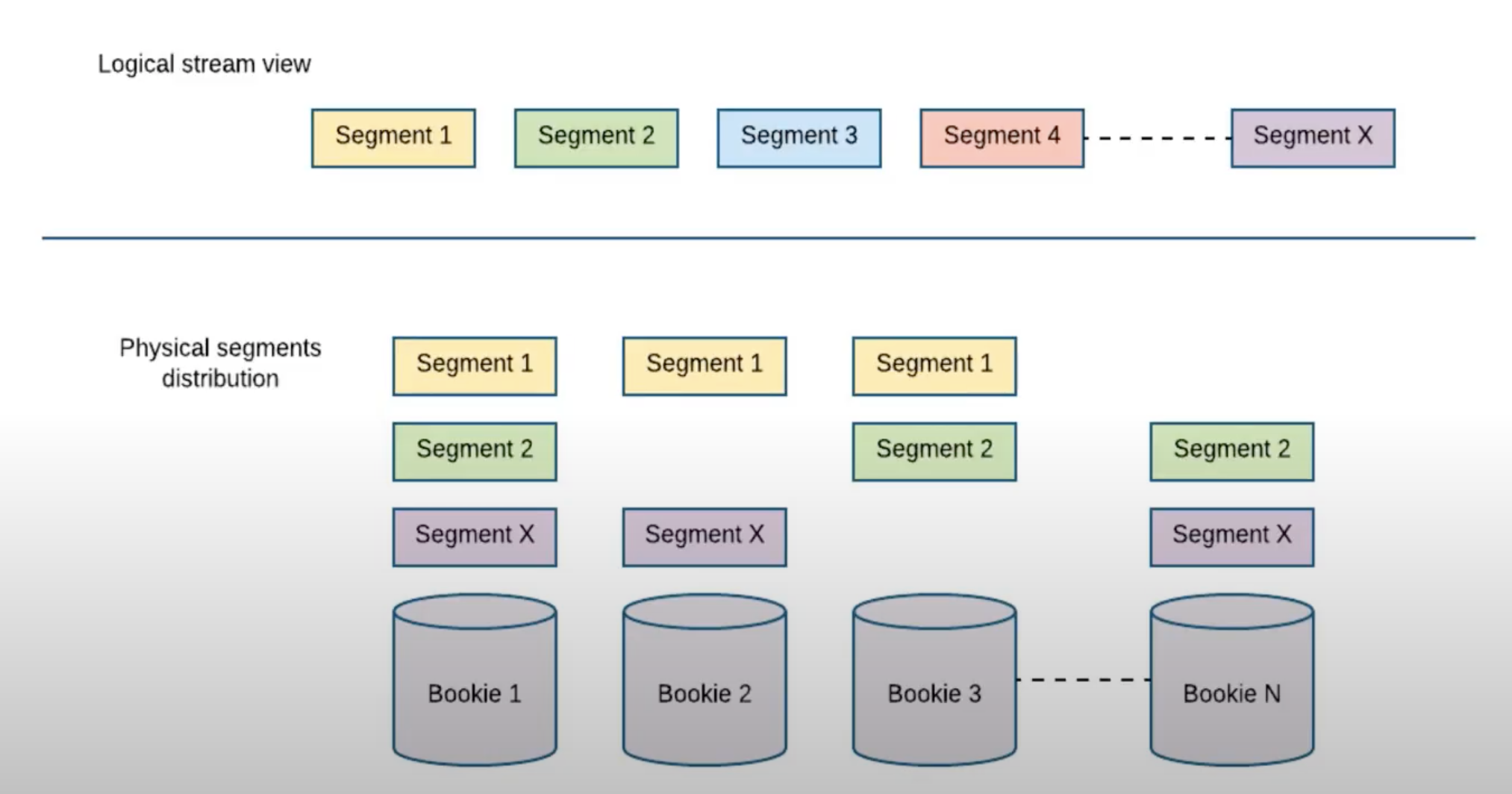
架构演变趋势
计算存储分离
Pulsar 是完全的计算存储分离架构,计算由 broker 来做,存储完成交给 bookkeeper。
计算存储分离在架构上的好处有哪些呢?
- Topic的容量可以无限扩张,不再受限于单个物理资源,你可以想一下基于本地磁盘版的 Kafka 做一个 SaaS 化的消息队列(类似 AWS 的 Kinesis)要怎么做?
- 集群的伸缩不再需要数据迁移(或者rebalance):这意味着集群可以快速扩容,在出现故障时,异常恢复时间也显著降低;
- 计算能力及存储能力可以独立扩展,对于消息的读写也可以独立扩展。
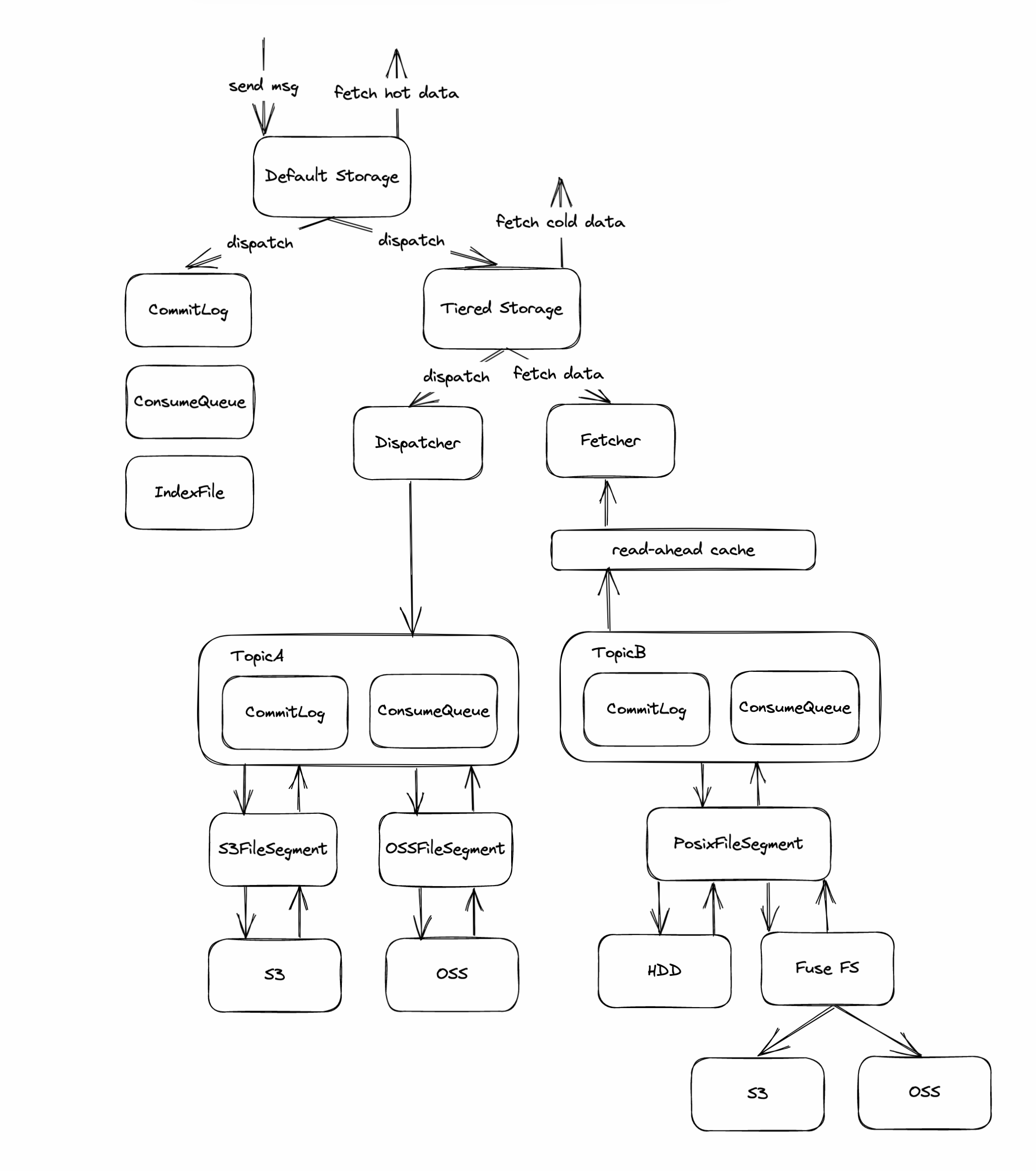
分层存储
RocketMQ 及 Kafka 为了支持计算存储分离的架构,采取了一个相对折中的策略:分层存储(tiered storage)。
分层存储架构(Tiered Storage)是一种高效的数据存储和管理方法,旨在优化存储系统的性能和成本效率。在这种架构中,数据被分散存储在不同类型的存储介质上,这些介质按照性能和成本的不同分为几个层级。这是一种通用的存储架构模式,不止是消息系统,数据库系统中也经常使用。
最主要的两个层级是热存储(Hot Storage)和冷存储(Cold Storage)。热存储通常使用更快速的存储介质,如SSD(固态硬盘),用于存储频繁访问的数据,以确保高性能和快速响应。相比之下,冷存储则使用成本较低的存储介质,如HDD(硬盘驱动器)或者远程存储(对象存储,HDFS等之类的),适用于存放访问频率较低的数据。
分层存储的关键优势在于它能够平衡性能和成本。通过将最活跃的数据保存在高性能的存储中,同时将较少使用的数据迁移到成本更低的存储上,可以在保证高效消息处理的同时,降低总体的存储成本。
RocketMQ 分层存储
RocketMQ tiered storage allows users to offload message data from the local disk to other cheaper and larger storage mediums. So that users can extend the message reserve time at a lower cost. And different topics can flexibly specify different TTL as needed.
Kafka 分层存储
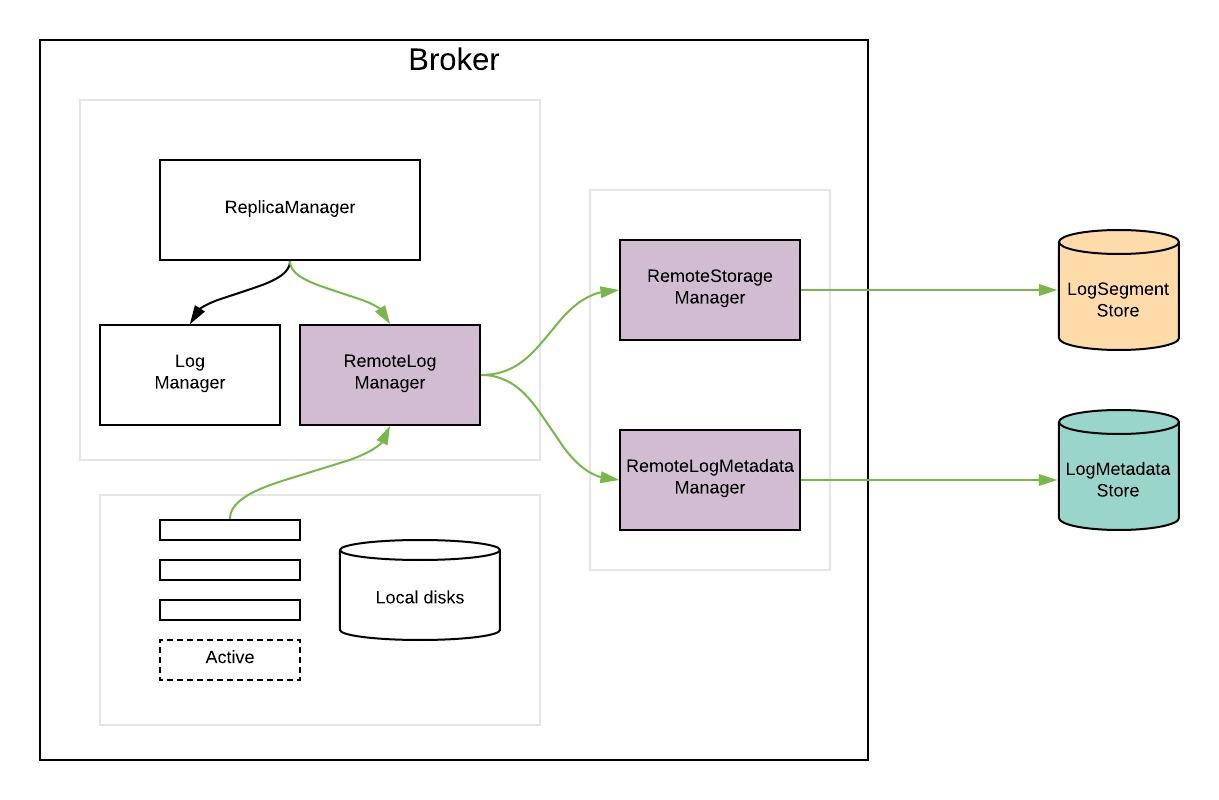
无盘化架构
无盘化也是计算存储分离架构,但不再依赖于本地磁盘或者云盘,而是完全依赖远程对象存储。
23.7 月,创业公司 Warpstream 发表了一篇文章 Kafka is dead, long live Kafka 主要吐槽了 Kafka 的架构在云环境下的成本问题:存储资源成本,高可用需要的数据复制带来的网络带宽成本,以及复杂的运维成本。为了解决这个问题,他们提出一个完全基于 AWS S3 的架构方案,可以把成本降到 1/10 甚至更少,但要牺牲延时(标准版 S3 的单次操作的延时在 100~200ms)。相比云盘,一方面显著降低资源及网络带宽成本,另一方面,因为整个存储都依赖 S3,可用性得到保证,并且运维成本显著降低。在实现上有两个关键点:
- 写入:有一个写入缓存,看他们创始人回答的一些信息来看,大概每 4MB 或者每 250ms 写入一次 S3;
- 读取:消息数据按一定策略分散到所有 broker 上,消费时直接从 broker 读取,broker 按需从 S3 读取,并且需要有预读取的能力。
23.11 月 AWS 发布了 S3 Express One Zone,成本高一点,但将单次操作的延时降到 10ms 以内,这个架构的可行性更高了。Warpstream 又发表了一篇 S3 Express is All You Need ,对延时有要求的场景,可以使用 S3 Express 来覆盖,但要付出相比 S3 Standard 更高的成本。
差不多同一时间,有位大神写了篇总结性很强的文章:S3 Express One Zone, Not Quite What I Hoped For,文章认可 S3 是现代云原生数据系统实现的重要基础,但当前 S3 Express 的价格偏高,还不够便宜。这篇文章对当前云原生数据系统的架构方案进行了很好的总结: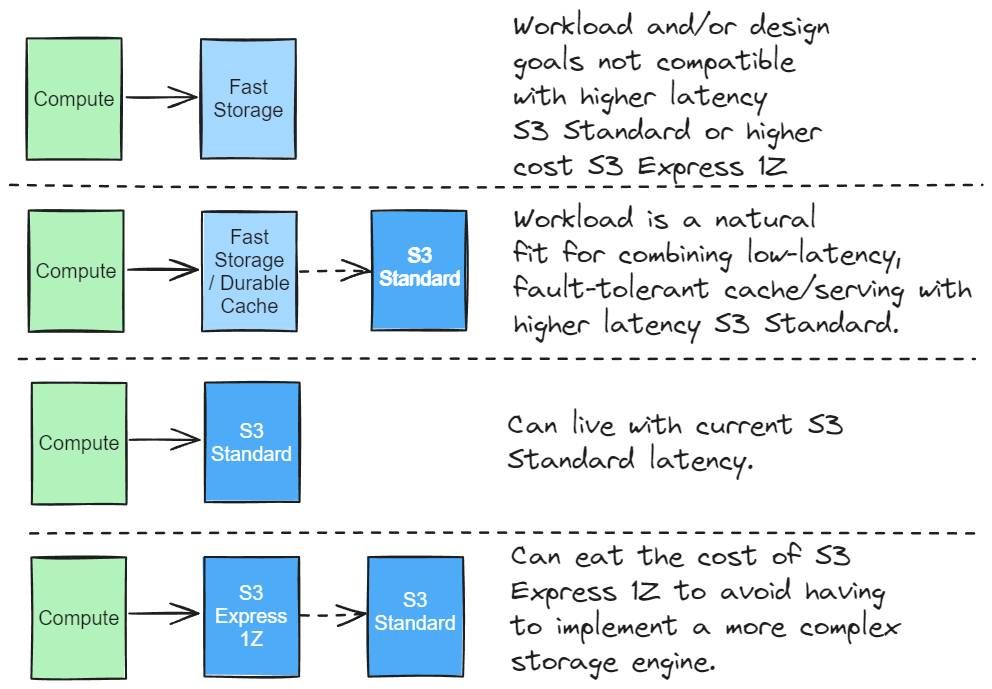
总结
现在的 RocketMQ 及 Kafka 处于第一种解决方案阶段,正在向第二种解决方案,也就是 Tiered Storage 演进。国内阿里云的消息队列核心研发创立的 AutoMQ,也是第二种解决方案,主要的方向就是基于 OSS 降低成本,看看他们的宣传语:
Automate everything that powers OSS Kafka, RocketMQ and RabbitMQ into the cloud-native era with AutoMQ. Reduce your cloud infrastructure bill by up to 90%.
Warpstream 目前属于第三种解决方案。
第四种方案,也就是以 S3 为基础,形成一个 S3 Express + S3 Standard 的分层构架:S3 Express 解决延时问题,S3 Standard 解决成本问题,会随着 S3 Express 的性能提升及价格降低,形成一个完全无盘化的架构趋势。
从研发的角度来看,存储完全依赖 S3,不但架构更清晰,代码也会更简单,上面介绍的 RocketMQ 及 Kafka 为了高可用而做的大量代码可能都不需要了。从运维的角度看,成本也是大幅降低,S3 本身有 SLA 保障,由云平台来运维,用户只需要维护无状态的计算结点,故障恢复逻辑也简单很多。